
Introducción
Después de presentar mi solución con el cliente se decidió a continuar por el camino del entrenamiento de nuestro propio modelo de lenguaje.
Para lograr el objetivo de tener un experto de productos, será necesario conocer a fondo el funcionamiento y la manera en la que interpreta los datos y los prompts que se le mencionen.
A continuación parecerá que voy a preparar mole de documentación, por que voy a desmenuzar la información de tal manera que sea fácil de tragar. Aunque no te fíes mucho de mí, te invito a que revises los documentos referenciados en los links para que tengas una visión más amplia.
Preparación
La solución planteada incluye un servidor python que nos funcionará como API para poder consultarlo de manera externa y pudiéndolo acoplar de mejor manera.
Si bien, en la propuesta de solución se menciona la creación de modelo de lenguaje entrenado con los datos de la empresa cliente, no mencioné que el cliente tiene planes a futuro los cuales incluyen:
- Experto en historia de urrea
- Experto en productos
- Experto en pronósticos
Es aquí donde nos encontramos con la primera área de oportunidad, ya que Langchain permite distintos tipos de entrenamiento. Entre los que permite se encuentran:
- Markdown
- Portable Document File
- Text File
- Comma-Separated Values
Esos son solamente algunos, conoce todos aquí.
Para cada forma de entrenamiento hay una forma diferente de ingresar los datos, ya que al final del día nuestro modelo es una réplica de los datos ingresados, por ende la calidad del modelo será inversamente proporcional a la información con la que se entrene.
¿Es magia?
Aunque la verdad me gustaría creerlo, no, el desarrollo de modelos de lenguaje no es magia. Aunque pueda parecer sorprendente la capacidad de generar texto coherente y relevante, hay una base científica y tecnológica detrás de ello.
En pocas palabras, el proceso de desarrollo de modelos de lenguaje se basa en el campo de la inteligencia artificial y el aprendizaje automático. Estos modelos se entrenan utilizando grandes conjuntos de datos de texto existentes, que les permiten aprender PATRONES y estructuras lingüísticas.
Por lo tanto, el desarrollo de un modelo de lenguaje exitoso implica un proceso riguroso que incluye la recopilación y preparación de datos, la elección de arquitecturas y algoritmos adecuados, el entrenamiento del modelo y la evaluación continua para garantizar su rendimiento óptimo.
Cuando hablamos de "patrones" en el fascinante mundo del desarrollo de modelos de lenguaje, nos referimos a esas hermosas y recurrentes regularidades que se encuentran en el texto. Son como pequeños destellos de estructuras gramaticales, secuencias de palabras comunes y estilos de escritura que se repiten una y otra vez. ¿Y sabes qué? ¡Estos patrones son la clave para desbloquear el poder de los modelos de lenguaje!
Imagina por un momento que estamos entrenando un modelo con datos. Durante este emocionante proceso, el modelo se dedica a identificar y capturar esos patrones, creando una especie de mapa del lenguaje en su interior. Es como si estuviera aprendiendo cómo se teje y se entrelaza cada palabra y cada frase en el tejido mágico del discurso humano.
Pero aquí viene lo más asombroso: una vez que el modelo ha absorbido esos patrones, los utiliza para generar texto que es coherente y relevante. Es como si estuviera canalizando su conocimiento interno del lenguaje para dar vida a palabras y oraciones que parecen surgir de la nada. ¡Es como si el modelo tuviera un poder especial para conjurar el lenguaje de forma casi mágica!
Sin embargo, no debemos olvidar que la calidad y diversidad de los datos de entrenamiento son fundamentales. Cuanto más ricos y variados sean los datos, mejor será la capacidad del modelo para reconocer y generar diferentes tipos de patrones lingüísticos. Alimentar al modelo con una dieta balanceada de información lingüística es clave para que pueda desplegar todo su potencial.
Para un correcto funcionamiento es primordial que la data ingresada tenga el patrón adecuado antes de ser cargada al código de Python.
Cada tupla tiene dos elementos:
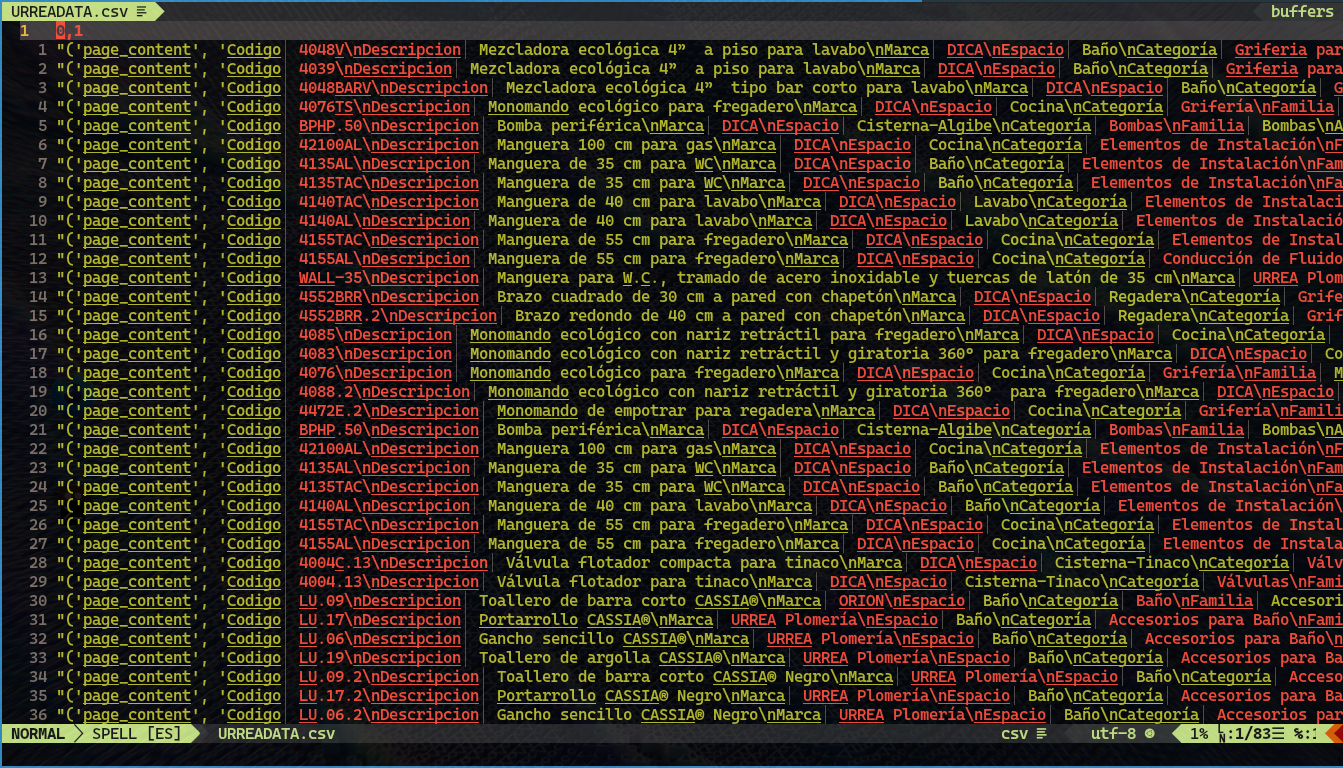
El primer elemento es una cadena de texto que contiene un código y una descripción del producto. Por ejemplo, se proporciona información sobre el código del producto, como "Codigo: 4048V" y una descripción asociada, como "Descripcion: Mezcladora ecológica 4” a piso para lavabo". Estos detalles brindan información específica sobre el producto en cuestión, como la marca, el espacio (baño o cocina), la categoría, la familia, el acabado y otros detalles relevantes.
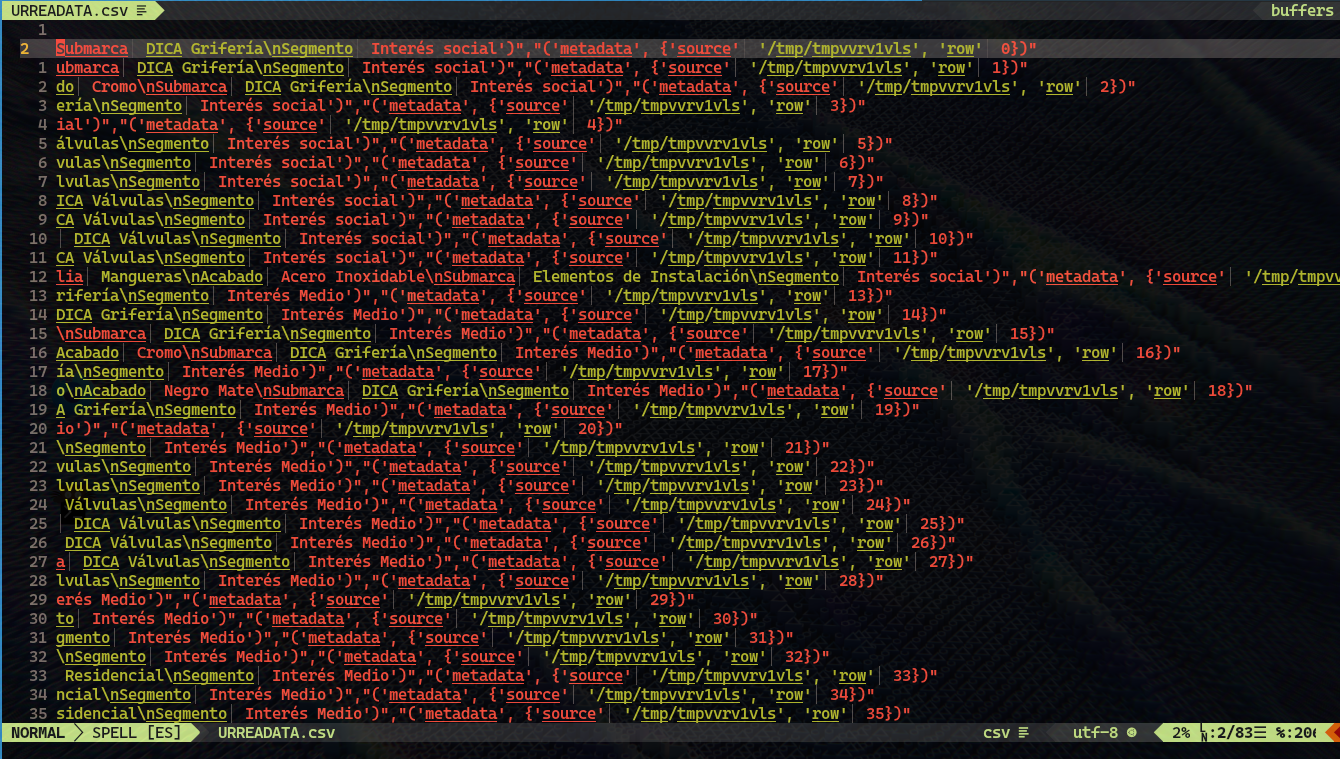
El segundo elemento de cada tupla es un diccionario que proporciona información adicional sobre la fuente y la fila de origen de los datos. Este diccionario incluye información como la fuente de los datos, representada por la clave "source", y la fila específica de donde se obtuvieron los datos, representada por la clave "row".
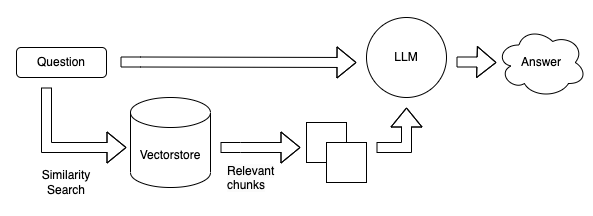
El diagrama muestra varios elementos interconectados que desempeñan roles específicos en el proceso de generación de respuestas con Langchain.
El punto de partida es el rectángulo etiquetado como "Question", el cual representa la pregunta o consulta inicial del usuario. Esta pregunta se dirige hacia dos direcciones clave: el Vectorstore y el LLM.
El Vectorstore, representado por otro rectángulo, recibe la pregunta y realiza una búsqueda de similitud utilizando un mecanismo específico llamado "Similarity search". Esta búsqueda tiene como objetivo encontrar elementos relacionados a la pregunta en la base de datos del Vectorstore. En otras palabras, el Vectorstore busca información similar o relevante a la pregunta planteada.
Simultáneamente, la pregunta también se envía al LLM (Language Model), representado por otro rectángulo en el diagrama. El LLM es un modelo de lenguaje que posee capacidades avanzadas de procesamiento del lenguaje natural. Utiliza la pregunta como entrada y genera una respuesta basada en su conocimiento previo y su capacidad para comprender el contexto.
Ahora, regresando al Vectorstore, este componente no solo realiza la búsqueda de similitud, sino que también proporciona fragmentos relevantes de información relacionados con la pregunta. Estos fragmentos se muestran en el diagrama como "Relevant Chunks" y son representados por un elemento conectado al Vectorstore. Estos fragmentos de información adicional son valiosos, ya que enriquecen el contexto disponible para generar una respuesta más precisa y completa.
Finalmente, los "Relevant Chunks" se conectan nuevamente con el LLM. Esta conexión implica que los fragmentos relevantes de información obtenidos del Vectorstore se utilizan como entrada adicional para mejorar la respuesta generada por el LLM. Al tener acceso a información más relevante y contextual, el LLM puede proporcionar una respuesta más informada y precisa al usuario.
- Vectorstore: Se llama así a nuestra "base de datos", es el lugar donde buscaremos si existe algo relacionado con el prompt ingresado por el usuario.
- Relevant Chunks: Son la información obtenida del Vectorstore considerada importante para dar una respuesta (al conectar al LLM) de manera más precisa.
Al mencionar que el prompt es importante me refiero a lo siguiente:
Imagina que tienes el control de un cañón láser (¡sí, suena sorprendente!) apuntando hacia un archivo de Excel, el cual es como una tabla de datos. En esta analogía, el prompt representa tu habilidad para apuntar con precisión. Cuanto más preciso seas al generar el prompt, mayor será la precisión del láser para alcanzar el dato correcto y disparar (es decir, obtener el dato deseado).
El diagrama representa un proceso donde una pregunta inicial se envía tanto al Vectorstore como al LLM. El Vectorstore realiza una búsqueda de similitud y proporciona fragmentos relevantes de información, que luego se utilizan junto con la pregunta original para mejorar la respuesta generada por el LLM. Esto sugiere un enfoque de búsqueda y recuperación de información para responder preguntas de manera más precisa y completa. Puedes encontrar más aquí
Data Science
Probablemente ya te tengo cansado con esto, pero me gustaría recordar la importancia que tienen los datos ingresados. Para poder visualizar los datos de una manera más rápida se pueden emplear herramientas como grep:
Filtrar filas que contengan palabras específicas en las columnas
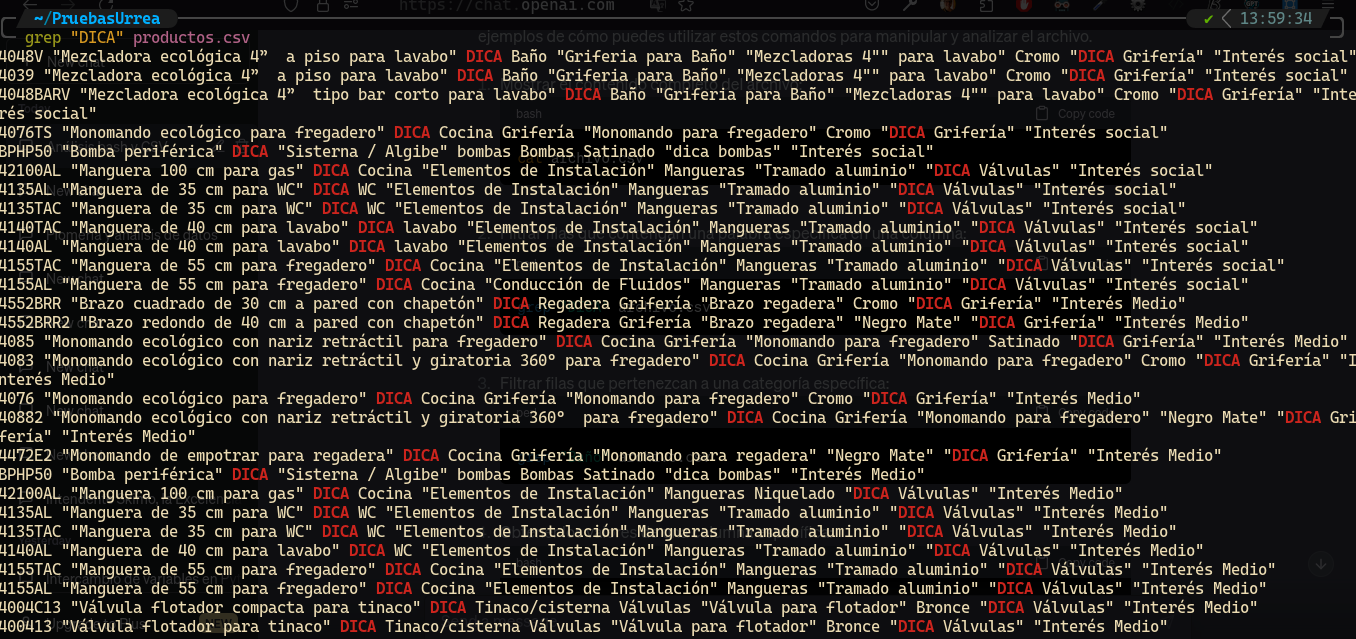
Filtrar filas que pertenezcan a una categoría en específica
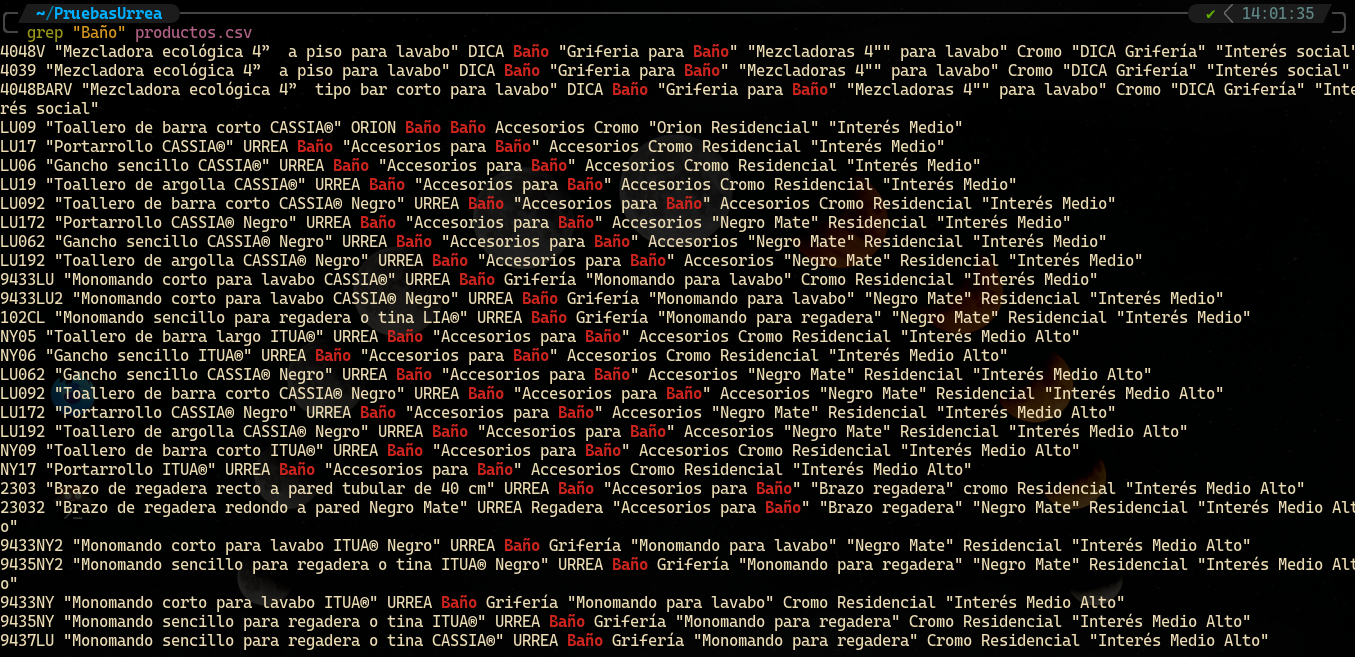
La aplicación correcta de la data science nos puede garantizar un modelo de lenguaje altamente capacitado para su uso.
Demostración
Se está realizando la demostración con el patrón mostrado anteriormente.
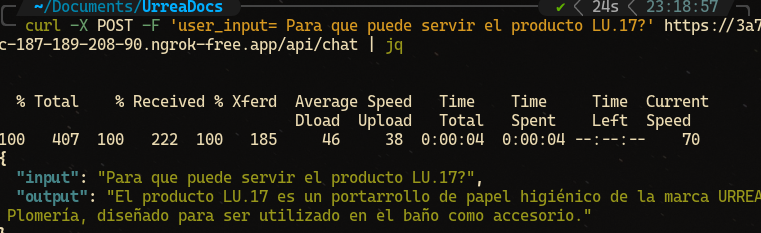
Como podemos ver el usuario está colocando un prompt que solicita al LLM información adicional que no tiene (el uso) y es aquí donde se hace uso de nuestro amigo gpt-3.5-turbo ya que el tiene contexto de lo que es el producto (debido a la vectorización y los relevant chunks) por ende puede hacer uso de su basto conocimiento para detectar que un "Portarrollo de papel higiénico" es para ser utilizado en el baño como accesorio.
Podemos ver los encabezados de nuestro archivo para poder corroborar que no se está especificando ningún campo de donde pueda consultar "el uso".
