
Introducción
Después de haber analizado las plataformas disponibles en el reporte comparativo y después de haber tenido la sesión presencial de toma de requerimientos por parte del cliente, se llegó a la conclusión de que ninguna de esas opciones cumplen con la idea principal de lo que se quiere. En su lugar se nos solicitó llevar acabo otra investigación acerca de una plataforma llamada WriteSonic, siendo más específicos, la herramienta que lleva por nombre "botsonic".
Creé una cuenta de la forma que menciona en la página web y empecé a explorar las opciones, de las cuales recuerdo:
- API : Tiene una API funcional.
- PDF : Permite entrenar al bot con los archivos subidos.
- URL : Permite ingresar una url como recurso.
- LLM : Crea un modelo de lenguaje entrenado con propia información.
Esta última opción llamó mi atención debido a que necesitamos obtener la mayor cantidad de datos (evidentemente datos pulidos) para poder entrenar de buena manera al bot Experto Urrea.
En la actualidad, el bot experto Urrea se encuentra entrenado con 9 fuentes de datos directamente extraídas de la tienda en línea www.urreashop.com. La posibilidad de generar un modelo de lenguaje personalizado con estos datos relevantes y depurados fue fundamental para lograr un entrenamiento óptimo. Reconocí la importancia de obtener una gran cantidad de datos de alta calidad para asegurar un rendimiento sólido y una comprensión profunda del lenguaje natural. Gracias a esta opción, pude aprovechar mi experiencia y conocimiento para entrenar al bot de manera efectiva, lo que se tradujo en respuestas más precisas y pertinentes para los usuarios.
¿Es buena idea?
Muchas veces cuando se está desarrollando un producto, suele atacar el gusanillo de ¿Pruebo esto...? ¿Pruebo esto otro otro?, esto se puede considerar "Lluvia de ideas" siempre y cuando sean preguntas que son tangibles en su respuesta.
Y por excelente idea que parezca se debe de tomar con pinzas, ya que en la mayoría de los casos no son tan buenas cuando las plasmamos en el punto de vista práctico, esto puede llegar a ocasionar frustración, sobre todo en las primeras fases donde no se tiene todavía claro lo que se requiere hacer. Bueno pues quiero evitar eso, por eso desglosé la solución de tal manera que pueda ser analizada de una manera más pulcra.
¿Por que vale la pena al menos intentarlo?
Esta es una de las preguntas más importantes debido a que la implementación de esta solución podría representar el pequeño paso que necesitaba hacía la que me gustaría llamar "La solución definitiva" la cual es el poder de la escalabilidad para poder tener integración hacía otros puntos de interés y esto se traduce a "Mayor cantidad de datos para entrenar".
Al entrenar el propio modelo de lenguaje "UrreaLM" se puede considerar y restablecer la estructura del proyecto de una manera más eficaz. Permitiendo:
Escalabilidad y adaptación
Al entrenar nuestro propio modelo de lenguaje, se tiene la oportunidad de crear una solución escalable que se adapte perfectamente a las necesidades específicas. Podemos diseñar la estructura del proyecto de manera eficiente, considerando los requisitos de datos, la complejidad del lenguaje y las tareas específicas que desea abordar. Esto le brinda un nivel de flexibilidad y personalización que es fundamental para lograr resultados óptimos.
Mayor cantidad de datos para entrenar
Al utilizar su propio modelo de lenguaje, puede aprovechar una mayor cantidad de datos para el entrenamiento. Esto es especialmente valioso en aplicaciones donde se requiere un conocimiento profundo del dominio específico. Al tener acceso a más datos relevantes y específicos, su modelo puede aprender patrones más complejos y sutiles, lo que se traduce en una mejor comprensión y generación de texto.
Control total sobre la calidad de los datos
Entrenar nuestro propio modelo de lenguaje nos permite tener un control total sobre la calidad de los datos utilizados. Puede realizar una exhaustiva limpieza y pre procesamiento de los datos para garantizar su integridad y relevancia. Además, puede aplicar técnicas de filtrado y refinamiento para eliminar el ruido y mejorar la calidad general de los datos de entrenamiento. Esto es esencial para obtener resultados confiables y precisos.
Exportación y reutilización
Otro beneficio clave de entrenar nuestro propio modelo de lenguaje es la capacidad de exportarlo y utilizarlo en otros proyectos o aplicaciones. Una vez que haya creado un modelo bien entrenado y optimizado, se puede guardar y utilizarlo en diferentes contextos. Esto puede ahorrarnos tiempo y esfuerzo,ya que no se tiene que entrenar un nuevo modelo desde cero cada vez que se enfrenta a un nuevo desafío. Además, incluso podríamos compartir su modelo con la comunidad, fomentando la colaboración y el avance en el campo del procesamiento del lenguaje natural. No solo para esa empresa, si no que para las demás.
En resumen, entrenar su propio modelo de lenguaje ofrece una serie de ventajas que no se pueden subestimar. Desde la flexibilidad y la adaptabilidad hasta el acceso a más datos y el control total sobre la calidad, usted está en condiciones de lograr resultados sobresalientes. Además, la capacidad de exportar y reutilizar su modelo le brinda una ventaja adicional en términos de eficiencia y colaboración. Así que, ¿por qué no aprovechar esta oportunidad y dar el paso hacia la creación de "La solución definitiva" que se adapte perfectamente a sus necesidades?
Solución
En el siguiente Link podrá visualizar la distribución y estructura del proyecto.
La cual se divide de la siguiente manera:
Scrapping
Con el objetivo de obtener un panorama completo y objetivo, se llevó a cabo un proceso de scrapping en la página principal de la tienda. Este proceso consistió en recopilar automáticamente información de la página web, explorando y extrayendo datos de todas las URLs que se desprendían de la URL principal. De esta manera, se realizó un escaneo exhaustivo de toda la página, permitiendo acceder a una amplia gama de información relevante.
El scrapping nos brindó la capacidad de recopilar datos de productos, descripciones, categorías y otros detalles relevantes que resultaron fundamentales para enriquecer el conjunto de datos utilizados en el entrenamiento del bot experto Urrea. Al explorar todas las páginas enlazadas desde la página principal, obtuvimos una visión más completa y detallada de los productos y servicios ofrecidos por la tienda en línea.
Este proceso de scrapping nos permitió obtener información actualizada y precisa directamente desde la fuente, lo que garantizó que nuestro bot experto Urrea estuviera respaldado por datos confiables y actualizados. Además, nos brindó la capacidad de realizar un análisis profundo de los datos y extraer patrones y tendencias que nos ayudaron a ofrecer respuestas más precisas y relevantes a los usuarios.
Exportar
Aunque la herramienta utilizada nos da la información directamente en pantalla con muchas acciones por realizar, nunca esta de más tener los datos de una manera externa, es decir exportar los datos, y en esta ocasión la herramienta previamente utilizada nos permite exportar los datos obtenidos a un archivo .csv, permitiéndonos un mejor manejo de la información obtenida. El archivo .csv nos exporta algo similar a esto:
| Address | Content Type | Status Code | Status | Indexability | Indexability Status | Title 1 | Title 1 Length | Title 1 Pixel Width | Title 2 | Title 2 Length | Title 2 Pixel Width | Meta Description 1 | Meta Description 1 Length | Meta Description 1 Pixel Width | Meta Keywords 1 | Meta Keywords 1 Length | H1-1 | H1-1 Length | H1-2 | H1-2 Length | H2-1 | H2-1 Length | H2-2 | H2-2 Length | Meta Robots 1 | X-Robots-Tag 1 | Meta Refresh 1 | Canonical Link Element 1 | rel="next" 1 | rel="prev" 1 | HTTP rel="next" 1 | HTTP rel="prev" 1 | amphtml Link Element | Size (bytes) | Word Count | Sentence Count | Average Words Per Sentence | Flesch Reading Ease Score | Readability | Text Ratio | Crawl Depth | Link Score | Inlinks | Unique Inlinks | Unique JS Inlinks | % of Total | Outlinks | Unique Outlinks | Unique JS Outlinks | External Outlinks | Unique External Outlinks | Unique External JS Outlinks | Closest Similarity Match | No. Near Duplicates | Spelling Errors | Grammar Errors | Hash | Response Time | Last Modified | Redirect URL | Redirect Type | Cookies | HTTP Version | URL Encoded Address | Crawl Timestamp |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| "https://urreashop.com/" | "text/html; charset=UTF-8" | "200" | "OK" | "Indexable" | "" | "UrreaShop" | "9" | "" | "0" | "0" | "Urreashop tienda oficial de URREA Válvulas, Urrea shop tiene llaves y accesorios para el baño y la cocina, refacciones, variedad de toalleros, llaves de cocina, lavabo, regaderas de las marcas URREA, DICA y STANZA a precios muy bajos económicos." | "247" | "1520" | "llaves de cocina, llaves de lavabo, monomandos, mezcladoras, válvulas, refacciones urrea, arbolitos, vástagos, cartuchos, accesorios de baño, urrea, shop, urreashop, urrea shop" | "176" | "Los más vendidos" | "16" | "" | "0" | "Categorías URREA SHOP" | "21 |
Pero recordemos que para crear el modelo "UrreaLM" es necesario escanear el contenido de las urls que se encuentren despues del Scrapping. Asi que con la ayuda del BashScript (como regularmente realizo las cosas) FroggyURL puedo guardar en un archivo .txt (urls.txt) únicamente las urls que se encuentran en el archivo internal_all.csv previamente exportado.
Organización
Como siempre, una buena organización y estructura se agradece debido a que facilita la comprensión y la navegación en cualquier proyecto. En el caso de nuestro proyecto "UrreaLM", hemos seguido una estructura clara y ordenada para garantizar un desarrollo fluido y eficiente.
En primer lugar, hemos dividido el proyecto en diferentes módulos y componentes, cada uno con una función específica. Esto nos permite mantener un código modular y fácil de mantener. Además, hemos seguido las mejores prácticas de nomenclatura y documentación para que el proyecto sea fácilmente comprensible por cualquier miembro del equipo.
Además de la organización a nivel de código, también hemos establecido un flujo de trabajo claro y definido. Esto incluye reuniones regulares para revisar el progreso del proyecto, asignación de tareas y seguimiento de los plazos establecidos. También hemos utilizado herramientas de gestión de proyectos y control de versiones para mantener un registro detallado de los cambios y facilitar la colaboración entre los miembros del equipo.
Este script lo que hace es que por cada linea del archivo "urls.txt" crea una carpeta con el nombre de la página a la cual está haciendo referencia y dentro de esta carpeta un archivo pdf con la información obtenida.
#!/bin/bash
# Autor: 4DRIAN0RTIZ
# Fecha: 12/05/2023
# Descripción: Este script convierte los archivos .txt a PDF. Si has utilizado FroggyURL, este es tu siguiente paso.
# Uso: ./job.sh <archivo>
# Ejemplo: ./job.sh internal_all.csv
# COLORES
RED='\033[0;31m'
GREEN='\033[0;32m'
PURPLE='\033[0;35m'
YELLOW='\033[1;33m'
CYAN='\033[0;36m'
BLUE='\033[0;34m'
WHITE='\033[1;37m'
ORANGE='\033[0;33m'
NC='\033[0m' # No Color
# Verificar si se proporciona un archivo como argumento
if [ $# -eq 0 ]; then
echo -e "${RED}Error:${NC} No se ha proporcionado ningún archivo"
echo -e "${ORANGE}Uso:${NC} ./job.sh <archivo>"
exit 1
fi
# Obtener el archivo del argumento
file=$1
# Verificar si el archivo existe
if [ ! -f "$file" ]; then
echo "Archivo no encontrado: $file"
exit 1
fi
# Leer las URLs del archivo
while read -r url; do
# Verificar si la URL no está vacía
if [ -n "$url" ]; then
# Utilizar w3m para obtener el contenido de la página web
content=$(w3m -dump "$url")
# Obtener el nombre del archivo PDF
filename=$(echo "$url" | awk -F[/:] '{for(i=4;i<=NF && i<=10;i++) printf "%s", $i; print ""}' | sed 's/^www\.//' | sed 's/\.com$//').pdf
# Guardar el contenido en un archivo temporal de texto
echo "$content" > temp.txt
# Generar el archivo PDF usando enscript y ps2pdf
enscript -p temp.ps temp.txt
ps2pdf temp.ps "$filename"
# Eliminar el archivo temporal
rm temp.txt temp.ps
echo "Guardado: $filename"
fi
done < "$file"
Se utilizó el script de bash mencionado para obtener el contenido del cuerpo (body) de las páginas web. La razón principal detrás de la elección de este script es la facilidad de implementación que ofrece para extraer el contenido deseado utilizando la herramienta w3m.
El script comienza verificando si se proporciona un archivo como argumento al ejecutarlo. Luego, lee las URLs del archivo y, para cada URL no vacía, utiliza el comando w3m para obtener el contenido de la página web. Este contenido se guarda temporalmente en un archivo de texto llamado "temp.txt".
A continuación, se utiliza el nombre de la URL para generar un nombre de archivo PDF correspondiente. Se emplean comandos como awk, sed y una serie de manipulaciones de cadenas para obtener un nombre legible y válido para el archivo PDF.
Posteriormente, el contenido almacenado en "temp.txt" se utiliza para generar un archivo PS (PostScript) utilizando el comando enscript. Finalmente, se convierte el archivo PS en un archivo PDF utilizando el comando ps2pdf. El archivo PDF resultante se guarda con el nombre generado previamente.
Una vez que se ha generado el archivo PDF, se elimina el archivo temporal "temp.txt" y "temp.ps". Por último, se muestra un mensaje indicando el nombre del archivo PDF guardado.
Esto significa que el script de bash facilita la extracción del contenido del cuerpo de las páginas web utilizando w3m, y luego genera archivos PDF correspondientes a partir de ese contenido. Esto proporciona una forma sencilla y eficiente de obtener la información requerida de las páginas web analizadas.
Costos
Bueno, pues no todo es color de rosa, al estar realizando las pruebas, me doy cuenta de que consume una cantidad considerable de tokens por cada entrenamiento, asi que eso yo lo llevaría con cuidado. Importante mencionar que se han generado 57851 tokens por únicamente 9 fuentes de información. Tomando como referencia la tabla de precios de OpenAI:
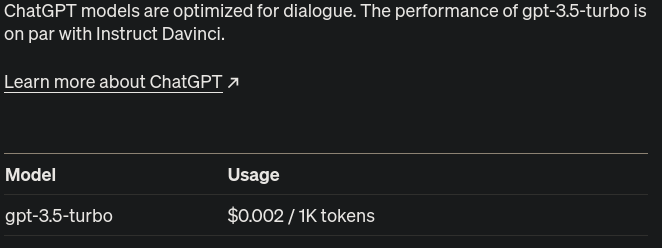
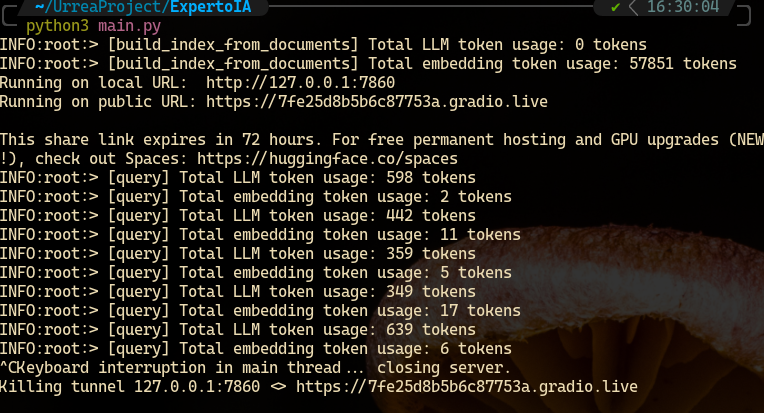
Al realizar la prueba con las 485 url encontradas se registraron un total de 3084122 tokens. Así que multiplicando el valor de $0.002 por el número de tokens, y después dividiéndolo entre 1000, tal como se muestra a continuación.

Es decir que sería un total de $6.168244 dólares. Usando el siguiente script:
mxn=$(curl -s https://api.exchangerate-api.com/v4/latest/USD | jq -r '.rates.MXN') ─╯
conversion=$(echo "6.168244 * $mxn" | bc)
echo "El equivalente de 6.168244 dólares en pesos mexicanos es: $conversion MXN"
Se obtiene el cambio actual del precio de la API.

Dando un total de 108.561094 pesos mexicanos. Entrenando una primera versión del bot con un total de 485 fuentes de información.
Las conversiones entre las divisas está en tiempo real. Si se quiere mantener actualizado sería necesario visitar frecuentemente la página de precios de OpenAI.
Esta información fue recopilada el 14 de mayo de 2023.
Prototipo
En mi repositorio de Github se encuentra el código fuente.
Es necesario contar con la Api Key de OpenAI. Crea un archivo .env y coloca:
OPENAI_API_KEY="<APITOKEN>"
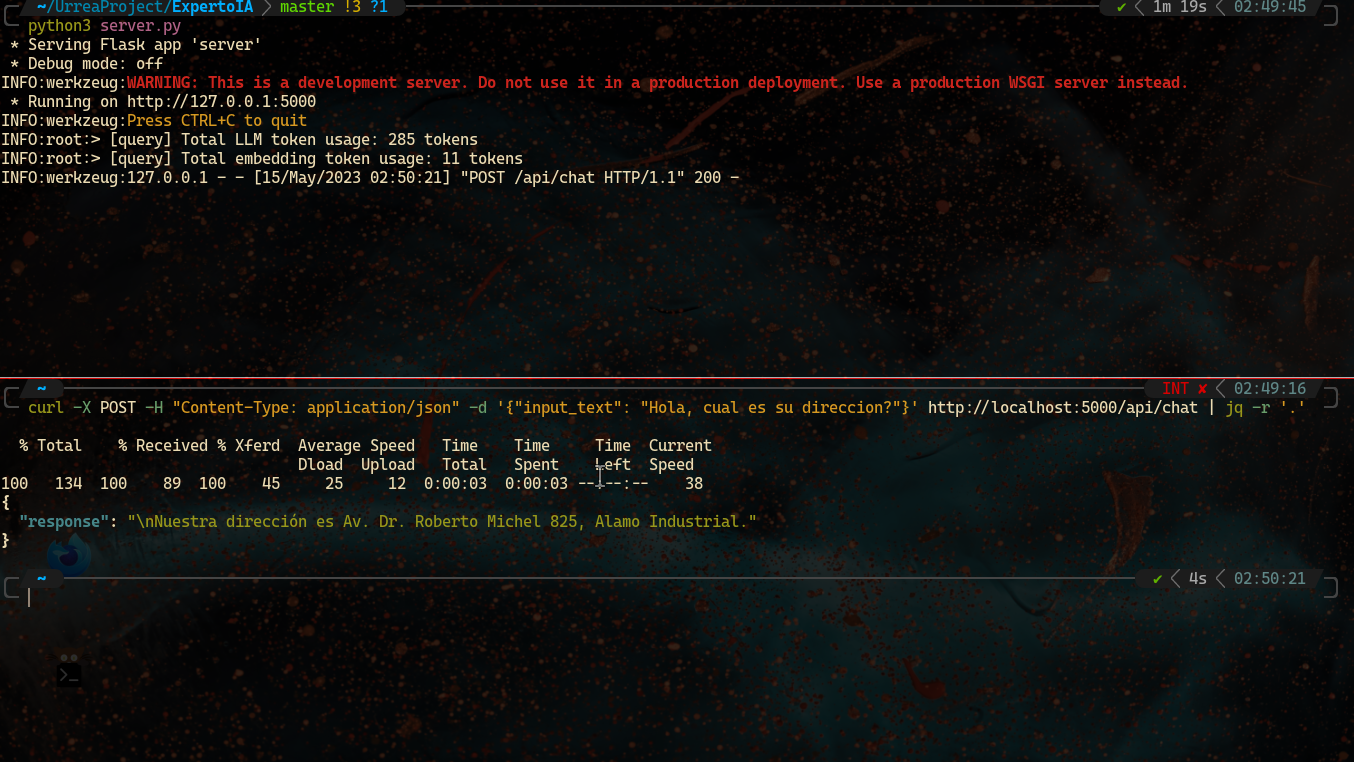
La siguiente imagen muestra el funcionamiento del lenguaje. En primer lugar se crea un servidor para la API con server.py. Después utilizando la herramienta CURL se envía una petición POST que es una consulta por la ubicación de la empresa. Se conecta con la API y UrreaLM devuelve una respuesta.
curl -X POST -H "Content-Type: application/json" -d '{"input_text": "Hola, cual es su direccion?"}' http://localhost:5000/api/chat | jq -r '.'
La implementación de UrreaML ofrece un gran potencial de escalabilidad y control. El entrenamiento personalizado de UrreaML mejora su comprensión y capacidad para generar respuestas precisas. El entrenamiento continuo y la retroalimentación constante mantienen la calidad y relevancia. Adoptar un enfoque centrado en el entrenamiento de UrreaML maximiza la precisión y coherencia de las respuestas. Con una infraestructura escalable, brindamos una experiencia fluida y confiable a medida que crece la demanda.