
Última actualización: 05 de Noviembre de 2025 a las 0:25
Introducción
Estos últimos días había estado pensando sobre que funcionalidad agregarle a mi actual bot que tengo en Discord "BKBOT". Pensando un poco recordé que los Echo Dot de Amazon tienen una funcionalidad que me gusta mucho, que es la de decirte un hecho histórico, solo con decirle "Echo, un día como hoy..." y te dice un hecho histórico de ese día. Entonces pensé, ¿por qué no hacer algo parecido en mi bot? Y así fue como se me ocurrió la idea de crear una API que me devuelva un hecho histórico de un día concreto.
Seré completamente honesto, lo que tenía en mente era buscar alguna API ya desarrollada, no importando si estaba en inglés, ya que podría traducirlo, para posteriormente solo hacer la petición desde BKBOT. Mi sorpresa fue que no encontré ninguna API que realizara dicha función (puede que exista pero no haya buscado bien, ese día tenía sueño). Así que como buen desarrollador, decidí hacer mi propia API con juegos de azar y mujerzuelas... ok no, solo con hechos históricos.
Obtención de datos
Sin una API ya desarrollada iba a tener que buscar manualmente los datos, lo cual no es muy eficiente, además soy demasiado "Programador" para hacer eso. Así que decidí buscar, pero ahora no una API, sino cualquier página web que contuviera la información que necesitaba, y así fue como encontré esta página que contiene hechos históricos de cada día del año, y lo mejor es que me ahorraría el trabajo de traducirlo, ya que están en español.

Con eso parecería que ya tenía todo lo que necesitaba, pero no, aún faltaba algo, y es que la página no tenía una opción para descargar la información, si lo sé, podría haber copiado y pegado, pero no, eso no es lo mío, en su lugar decidí hacer Web Scraping para obtener los datos que necesitaba. Para ello utilicé la librería Beautiful Soup de Python, la cual es muy útil para extraer datos de archivos HTML y XML. No entraré en detalles de cómo funciona, pero si quieres saber más sobre Web Scraping puedes leer este artículo.
Pareciera que Alberto Varela quién es el autor de la web estaba consciente de que algún día alguien necesitaría extraer los datos, ya que el código HTML está muy bien estructurado, lo cual facilitó mucho el trabajo. Así que solo tuve que obtener el HTML de la página y buscar los datos que necesitaba. Para ello utilicé el inspector de elementos de Firefox, el cual es muy útil para saber la estructura de una página web y así poder extraer los datos que necesitas. En la siguiente imagen se muestra la estructura de la página web.
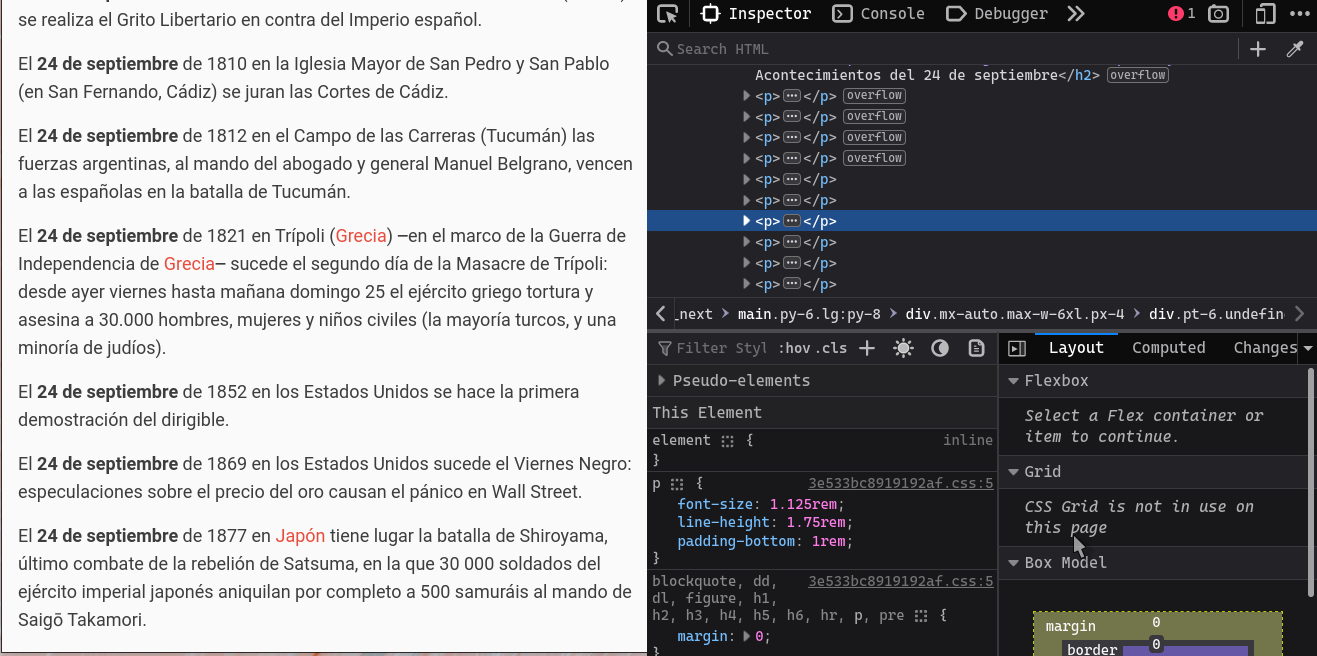
Cada uno de los hechos históricos están minuciosamente estructurados en elementos <p>, así que solo tuve que buscar los elementos <p> y obtener su texto. ¿Simple, no?
Pero si quería realmente automatizarlo y obtener todas las efemérides en un solo click hacía falta otra pequeña cosa, y es que la página muestra las efemérides de cada día en una página diferente. Pero insisto, Alberto Varela es un buen desarrollador y tiene una URL para cada día del año, estructurada de la siguiente manera: https://www.efemerides20.com/{dia}-de-{mes}. Así que solo tuve que crear un bucle para recorrer todos los días del año y obtener los datos.
Para eso utilicé el siguiente código:
import requests
from bs4 import BeautifulSoup
# URL base de la página web
base_url = "https://www.efemerides20.com/"
# Diccionario para mapear los nombres de los meses a sus números
meses = {
"enero": 1,
"febrero": 2,
"marzo": 3,
"abril": 4,
"mayo": 5,
"junio": 6,
"julio": 7,
"agosto": 8,
"septiembre": 9,
"octubre": 10,
"noviembre": 11,
"diciembre": 12
}
# Bucle para recorrer los meses
for nombre_mes, num_mes in meses.items():
# Bucle para recorrer los días (de 1 a 31)
for dia in range(1, 32):
# Comprobar si la fecha es válida (por ejemplo, no todos los meses tienen 31 días)
if num_mes == 2 and dia > 28:
continue
elif (num_mes in [4, 6, 9, 11]) and dia > 30:
continue
# Crear la URL para la fecha actual
url = f"{base_url}{dia}-de-{nombre_mes}"
# Realizar una solicitud GET a la página web
response = requests.get(url)
# Comprobar si la solicitud fue exitosa
if response.status_code == 200:
# Parsear el contenido de la página con BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Obtener el texto de todos los elementos <p>
parrafos = soup.find_all('p')
# Crear el nombre del archivo
nombre_archivo = f"efemerides_{dia:02d}_{num_mes:02d}.txt"
# Guardar el texto en un archivo
with open(nombre_archivo, 'w', encoding='utf-8') as archivo:
for parrafo in parrafos:
archivo.write(parrafo.get_text() + '\n')
print(f"Guardado: {nombre_archivo}")
else:
print(f"Error al acceder a la página web para {dia:02d}-{num_mes:02d}: {response.status_code}")
Ese código se iba a encargar de guardar cada efeméride en un archivo de texto, con el siguiente formato: efemerides_{dia}_{mes}.txt. Por ejemplo, el archivo efemerides_01_01.txt contiene las efemérides del 1 de enero. El archivo efemerides_01_02.txt contiene las efemérides del 1 de febrero, y así sucesivamente.
El resultado final se ve algo así:
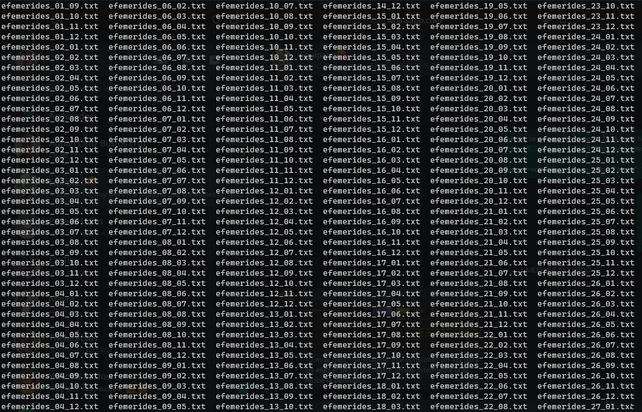
Y así es como obtuve los datos que necesitaba.
Limpieza de datos
Una vez que obtuve los datos, me di cuenta que no todo era tan bonito como parecía, ya que los datos contenían basura, y aunque no era tanta, no quería arriesgarme a que mi bot publicara algo como "Un proyecto de Alberto Varela | FAQ | Aviso legal | Política de privacidad | Política de cookies Only free software was used and no kitties were harmed in the making of this website." (si no entiendes la referencia, lee el código fuente de la página web).
Si hacemos un cat a uno de los archivos de texto, podemos ver que contiene basura al principio y al final:

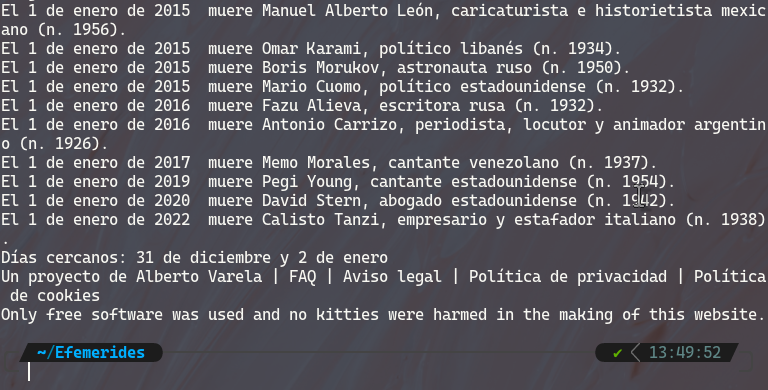
Son específicamente las primeras 2 líneas y las últimas 3 líneas, así que solo tuve que eliminarlas. Para ello utilicé sed.
for archivo in efemerides_*.txt; do
sed -i '1,2d' "$archivo" # Elimina las 2 primeras líneas
done
for archivo in efemerides_*.txt; do
sed -i '$d' "$archivo" # Elimina la última línea
sed -i '$d' "$archivo" # Elimina la penúltima línea
sed -i '$d' "$archivo" # Elimina la antepenúltima línea
done
Como se puede ver en la imagen de arriba, existían 2 espacios entre el año y el texto, así que también tuve que eliminarlos.
for archivo in efemerides_*.txt; do
sed -i 's/ */ /g' "$archivo" # Reemplaza múltiples espacios por uno solo
done
Con esto pude limpiar mis datos y dejarlos listos para ser utilizados.
Desarrollo de la API
Si leíste mi artículo VPS como entorno de producción, sabrás que estoy bastante familiarizado con el uso del framework Flask, así que decidí utilizarlo para crear mi API.
El concepto general es simple: crear un endpoint que reciba una fecha dd_mm, busque si existe algún archivo de texto con ese nombre y me devuelva una línea aleatoria del archivo. Recordemos que el nombre de los archivos de texto es efemerides_{dia}_{mes}.txt, así que si el endpoint recibe 01_01, buscará el archivo efemerides_01_01.txt y devolverá una línea aleatoria.
from flask import Flask, request, jsonify
import os
import random
app = Flask(__name__)
app.config['JSON_AS_ASCII'] = False
# Ruta para manejar la solicitud de efemérides
@app.route('/obtener_efemeride', methods=['POST'])
def obtener_efemeride():
data = request.json # Recibe los datos JSON
fecha = data.get('fecha') # Busca la fecha en el JSON
if not fecha or len(fecha) != 5:
return jsonify({"error": "La fecha no es válida. Use el formato dd_mm."}), 400
# Componer el nombre del archivo
archivo_efemerides = f"efemerides/efemerides_{fecha}.txt"
# Verificar si el archivo existe
if not os.path.exists(archivo_efemerides):
return jsonify({"error": "No se encontraron efemérides para esta fecha."}), 404
# Leer el contenido del archivo
with open(archivo_efemerides, 'r', encoding='utf-8') as archivo:
lineas = archivo.readlines()
# Seleccionar una línea aleatoria
efemeride_aleatoria = random.choice(lineas).strip()
return jsonify({"efemeride": efemeride_aleatoria})
if __name__ == '__main__':
app.run(debug=True)
Y vualá, ya tenemos la API funcionando, la desplegamos en Heroku y ya tenemos nuestra API lista para ser consumida.
Petición a la API
Para lograr el mismo efecto de los dispositivos Echo, decidí hacer que el bot respondiera a "!UnDiaComoHoy" previamente formateando mi fecha actual dd_mm y enviándola a la API. Para ello utilicé la librería requests de Python. No colocaré todo el código de mi Bot "BKBOT" por que posiblemente más adelante escriba un artículo sobre como crear un bot de Discord, pero si colocaré la parte que hace la petición a la API.
async def dia_hoy(message):
try:
# Formatea la fecha actual en DD_MM
fecha_actual = datetime.now().strftime("%d_%m")
# Se crea el objeto JSON con la fecha actual
data = {"fecha": fecha_actual}
# URL
url = "https://un-dia-como-hoy-9cd4a11cc8ae.herokuapp.com/obtener_efemeride"
# Encabezados HTTP
headers = {"Content-Type": "application/json"}
# Realizar la solicitud POST
response = requests.post(url, headers=headers, data=json.dumps(data))
# Verificar si la solicitud fue exitosa
if response.status_code == 200:
embed = discord.Embed(color=discord.Color.blue())
# Obtener la respuesta JSON
response_json = response.json().get('efemeride')
# Enviar la respuesta como un mensaje al canal
embed = discord.Embed(color=discord.Color.blue())
embed.add_field(name="Un día como hoy...", value=response_json, inline=False)
await message.channel.send(embed=embed)
else:
await message.channel.send(f"La solicitud falló con el código de respuesta: {response.status_code}")
except Exception as e:
await manejador_excepciones(message, str(e))
Prueba la API
El formato de la petición en CURL sería el siguiente:
curl -X POST -H "Content-Type: application/json" -d '{"fecha": "27_06"}' https://un-dia-como-hoy-9cd4a11cc8ae.herokuapp.com/obtener_efemeride
En lugar de CURL puedes utilizar Postman o Insomnia para realizar la petición, inclusive cualquier lenguaje de programación que tenga la capacidad de realizar peticiones HTTP. Lo coloco con curl por que es el que uso y además es fácil convertirlo a código de otros lenguajes.
Resultado
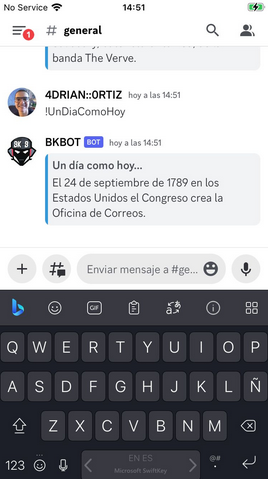
Todo trabajo tarde o temprano rinde frutos y este no fue la excepción. Nuestro bot BKBOT ya cuenta con esta nueva funcionalidad y ahora podemos obtener una efeméride de forma aleatoria todos los días.
Conclusión
Este pequeño proyecto de una semana demuestra el poder de la programación para dar vida a ideas innovadoras y creativas. Aunque no es algo que vaya a cambiar el mundo, si es algo que puede alegrar el día de alguien y eso es lo que me motiva a seguir aprendiendo y creando. A través de la magia de la programación, pudimos conectar el pasado con el presente. Desde La Cueva Del NeanderTech esperamos que hayas disfrutado de este artículo y que te haya gustado el proyecto. Si tienes alguna duda o sugerencia, no dudes en dejarla en los comentarios.
Actualizaciones
Bueno, hace ya cerca de 2 años que escribí este artículo, y después de tanto tiempo, creo que la API pide a gritos un Frontend, así que decidí crear una página web para acceder. Con la peculiaridad qque puedes subir una foto mediante una PR a mi repositorio de GitHub, y la página web la mostrará junto con la efeméride del día. Puedes ver el resultado final en este enlace.
Si puedes imaginarlo, puedes programarlo.
— Alejandro Taboada