
Introducción
Desde que conocí las API Rest me enamoré de ellas, desde su simplicidad hasta la furia de su complejidad, y de Bash ni se diga, gracias a él me considero un buen ScriptScultor. Dado que me robaron un día y pensaba que la FMS era el sábado (fue el viernes 12) tuve un fin de semana dedicado completamente a cacharrear.
Dentro de la inmensa cantidad de disparates que pasaban por mi cabeza, se me ocurrió desarrollar una API Rest usando Bash. Y de eso vengo a hablarles hoy.

Netcat
Primero lo primero, antes de ponerme a hacer cualquier cosa tuve que averiguar cómo poder hacer la interacción entre el cliente y servidor. Y es ahí donde entra Netcat, permitiendo hacer la función de un servidor TCP/UDP y un cliente TCP/UDP. Esto con la finalidad de escuchar las peticiones que lleguen a un puerto en específico y responder a ellas.
Un diagrama sencillo sería el siguiente:
┌─────────────────────────────────────────────────────────────────────────────┐
│ COMUNICACIÓN NETCAT │
└─────────────────────────────────────────────────────────────────────────────┘
Terminal 1: Server FIFO Pipe Terminal 2: Process
────────────────── ─────────── ─────────────────
$ ./server.sh
┌─────────────┐ ┌─────────┐ ┌─────────────┐
│ │ │ │ │ │
│ nc -l -p │ │ PIPE │ │ api.sh │
│ 8081 │ │ (FIFO) │ │ │
│ │ │ │ │ │
│ INPUT ┌──┼──────────────┼────────►┼────────────┼───┐ STDIN │
│ ▲ │ │ │ │ │ │ ▼ │
│ │ │ │ │ │ │ │ Parse │
│ │ │ │ │ │ │ │ Route │
│ OUTPUT │ │ │ │ │ │ Execute │
│ │ │ │ │ │ │ │ │ │
│ │ └──┼──────────────┼◄────────┼────────────┼───┘ STDOUT │
│ ▼ │ │ │ │ ▼ │
└─────────────┘ └─────────┘ └─────────────┘
│ │
▼ ▼
Client receives Process exits
HTTP response (one request)
Ciclo de vida:
1. nc escucha en puerto 8081
2. Cliente conecta y envía HTTP request
3. nc recibe request → pipe → api.sh (STDIN)
4. api.sh procesa → genera response → pipe (STDOUT)
5. nc lee response del pipe → envía al cliente
6. Conexión se cierra, api.sh termina
7. nc vuelve a escuchar (loop en server.sh)
Aunque es más complejo de lo que parece, ya que netcat pasa los datos por la entrada estándar y la salida estándar, por lo que tuve que ingeniármelas para poder capturar las peticiones y responder a ellas. Esto implica tener que parsear las peticiones HTTP, lo cual no es tarea fácil, pero con un poco de ingenio y paciencia se puede lograr. Para ello me tocó meterme al más bajo nivel de HTTP, es decir, tener que entender cómo funciona el protocolo HTTP y cómo se estructuran las peticiones y respuestas. Aunque me costó horas de comida en mi actual trabajo, logré entenderlo y poder implementarlo en Bash.
Socket
Con los sockets podemos crear una comunicación entre dos procesos, en este caso entre el cliente y el servidor. Netcat utiliza sockets para escuchar en un puerto específico y aceptar conexiones entrantes. Cuando un cliente se conecta, netcat crea un nuevo socket para esa conexión, lo que permite la comunicación bidireccional entre el cliente y el servidor.
nc -Uvl server.sock
Esto crea un socket Unix llamado server.sock y escucha conexiones entrantes. La opción -U indica que es un socket Unix, -v habilita el modo verbose para ver más detalles, y -l indica que netcat debe escuchar en lugar de iniciar una conexión.
Esto es del lado del servidor, pero del lado del cliente sería algo así:
nc -Uv server.sock
Con esto el cliente se conecta al socket Unix server.sock. La opción -U indica que es un socket Unix, y -v habilita el modo verbose para ver más detalles. Con esto podemos empezar a enviar y recibir datos a través del socket.
HTTP
Es mi pan de cada día, pero nunca me había puesto a pensar en cómo funcionaba realmente, o sea, sé que significa Hypertext Transfer Protocol pero generalmente siempre uso librerías que me abstraen de todo eso, o herramientas como curl o posting que me facilitan la vida. Pero en esta ocasión tuve que ponerme a pensar en cómo funcionaba realmente, y es ahí donde me di cuenta de que es más complejo de lo que parece.
Primero me di cuenta de que hay un HTTP Request y un HTTP Response, ambos tienen una estructura similar, pero con diferencias importantes. El HTTP Request tiene una línea de inicio, seguida de una serie de cabeceras y un cuerpo opcional. La línea de inicio tiene el método HTTP (GET, POST, PUT, DELETE, etc.), la URL y la versión del protocolo. Las cabeceras son pares clave-valor que proporcionan información adicional sobre la petición. El cuerpo es opcional y se utiliza para enviar datos al servidor.
HTTP Request
Esto es lo que un cliente envía al servidor, un ejemplo sencillo de una petición GET sería el siguiente:
GET / HTTP/1.1
Host: localhost:8081
Connection: close
Esto traducido a Bash sería algo así:
echo -e "GET / HTTP/1.1\r\nHost: localhost:8081\r\nConnection: close\r\n\r\n" | nc localhost 8081
El \r\n es el salto de línea en HTTP, y el \r\n\r\n al final indica el fin de las cabeceras.
SIEMPRE debe haber un salto de línea al final de las cabeceras, incluso si no hay cuerpo.
HTTP Response
Pero una petición POST con un cuerpo sería algo así:
POST /api/data HTTP/1.1
Host: localhost:8081
Content-Type: application/json
Content-Length: 27
Connection: close
echo -e 'HTTP/1.1 200 OK\r\nContent-Type: application/json\r\n{"message": "Hello, World!"}' | nc localhost 8081
- HTTP/1.1 200: Esta es la línea de estado que indica que la petición fue exitosa.
200es un código de estado estándar que significa que la solicitud se ha procesado correctamente. - Content-Type: application/json: Esta cabecera indica que el cuerpo de la respuesta está en formato JSON. Esto es importante para que el cliente sepa cómo interpretar los datos recibidos. Podemos enviar más de un header, separados por saltos de línea.
- Empty Line: Una línea vacía (
\r\n) que indica el final de las cabeceras y el comienzo del cuerpo de la respuesta.
Tuve que construir una función en Bash que me permitiera generar estas respuestas de manera dinámica, dependiendo de la petición recibida.
http_response() {
local status_code="$1"
local content_type="$2"
local body="$3"
local content_length=$(printf '%s' "${body}" | wc -c)
echo -e "HTTP/1.1 ${status_code}\r"
echo -e "Content-Type: ${content_type}\r"
echo -e "Content-Length: ${content_length}\r"
echo -e "Access-Control-Allow-Origin: *\r"
echo -e "Access-Control-Allow-Methods: GET, POST, PUT, DELETE, OPTIONS\r"
echo -e "Access-Control-Allow-Headers: Content-Type, Authorization\r"
echo -e "\r"
printf '%s' "${body}"
}
Un ejemplo de uso sería:
http_response "200 OK" "application/json" '{"message": "Hello, World!"}' # Para respuestas con cuerpo
http_response "204 No Content" "text/plain" "" # Para respuestas sin cuerpo
http_response "404 Not Found" "text/plain" "Resource not found" # Para respuestas de error
http_response "500 Internal Server Error" "text/plain" "Internal server error" # Para respuestas de error
Con esto ya tenía la base para poder responder a las peticiones que llegaran al servidor, pero aún faltaba lo más importante, el enrutamiento y la ejecución de las funciones correspondientes a cada ruta.
Enrutamiento
Parecerá sencillo, pero no lo es, recordemos que estamos en Bash, y no tenemos las facilidades que nos ofrecen otros lenguajes de programación. Y dado que quería un framework hecho y derecho, tuve que buscar la forma de que sea dinámico y fácil de usar.
┌────────────────────────────────────────────────────────────────┐
│ REGISTRO DE RUTAS │
└────────────────────────────────────────────────────────────────┘
load_routes("routes/")
│
▼
┌─────────────────┐
│ routes/ │
│ ├── root.sh │ ──┐
│ ├── users.sh │ │ source cada archivo
│ └── *.sh │ │
└─────────────────┘ │
│ │
▼ │
┌─────────────────────┼─────────────────────┐
│ REGISTERED_ROUTES[] │ │ Arrays globales
│ ROUTE_HANDLERS{} │ │ en router.sh
│ ROUTE_PATTERNS{} │ │
└─────────────────────┘ │
│
register_route(method, pattern, handler) ◀──┘
┌─────────────────────────────────────────┐
│ "GET /users" → "get_users" │
│ "POST /users" → "post_users" │
│ "GET /users/{id}" → "get_user" │
│ "PUT /users/{id}" → "put_user" │
│ "DELETE /users/{id}" → "delete_user" │
└─────────────────────────────────────────┘
Lo que hago es que cada archivo en la carpeta routes/ define sus propias rutas y las registra en un array global. Esto permite que el framework sea modular y fácil de extender. Cada archivo de ruta puede contener múltiples definiciones de rutas, y todas se cargan automáticamente cuando se inicia el servidor. Con la función register_route puedo asociar un método HTTP y una ruta con una función manejadora específica.
Algo así:
register_route "GET" "/users" "get_users"
Eso me permite definir que cuando llegue una petición GET a la ruta /users, se ejecute la función get_users. ¿Interesante, no?
Y mi función register_route se ve así:
register_route() {
local method="$1"
local pattern="$2"
local handler="$3"
local route_key="${method} ${pattern}"
REGISTERED_ROUTES+=("$route_key")
ROUTE_HANDLERS["$route_key"]="$handler"
ROUTE_PATTERNS["$route_key"]="$pattern"
}
Con esto solamente tengo que preocuparme por definir mis rutas y funciones manejadoras, y el framework se encarga del resto.
Base de datos
Pero, ¿Y si quiero tener una base de datos? Para eso tengo la solución perfecta, SQLite. Es una base de datos ligera y fácil de usar, y lo mejor de todo es que no requiere un servidor separado, ya que se almacena en un solo archivo. Esto es perfecto para un proyecto como este, donde quiero mantener las cosas simples y fáciles de desplegar. Por qué no iba a conectar una API de Bash a Azure SQL, ¿o sí?
Pensaba en hacer solo una función que me permitiera ejecutar consultas SQL, pero seamos realistas, es mucho mejor tener funciones específicas para las operaciones CRUD (Crear, Leer, Actualizar, Eliminar). Esto hace que el código sea más limpio y fácil de entender. Y por supuesto, puedo usar parámetros para hacer las consultas más dinámicas.
# SQLite utilities
db_query() {
local query="$1"
local format="${2:-table}"
execute_query "$query" "$format"
}
db_query_json() {
local query="$1"
sqlite3 "$DB_FILE" -json "$query"
}
db_insert() {
local table="$1"
local fields="$2"
local values="$3"
sqlite3 "$DB_FILE" "INSERT INTO $table ($fields) VALUES ($values);"
}
db_update() {
local table="$1"
local set_clause="$2"
local where_clause="$3"
sqlite3 "$DB_FILE" "UPDATE $table SET $set_clause WHERE $where_clause;"
}
db_delete() {
local table="$1"
local where_clause="$2"
sqlite3 "$DB_FILE" "DELETE FROM $table WHERE $where_clause;"
}
db_select() {
local table="$1"
local fields="${2:-*}"
local where_clause="$3"
local format="${4:-json}"
local query="SELECT $fields FROM $table"
if [ -n "$where_clause" ]; then
query="$query WHERE $where_clause"
fi
db_query "$query" "$format"
}
db_count() {
local table="$1"
local where_clause="$2"
local query="SELECT COUNT(*) FROM $table"
if [ -n "$where_clause" ]; then
query="$query WHERE $where_clause"
fi
sqlite3 "$DB_FILE" "$query"
}
db_exists() {
local table="$1"
local where_clause="$2"
local count=$(db_count "$table" "$where_clause")
[ "$count" -gt 0 ]
}
db_get_last_insert_id() {
sqlite3 "$DB_FILE" "SELECT last_insert_rowid();"
}
db_get_changes() {
sqlite3 "$DB_FILE" "SELECT changes();"
}
Ya va agarrando forma el proyecto, ¿no creen?
Pero esto tiene que estar mucho mejor, por que surgen preguntas:
- ¿Tengo que crear las tablas manualmente?
- ¿Y si quiero cambiar la estructura de la base de datos?
SOLUCIÓN: Migraciones
Migraciones
Es un concepto que vengo usando desde hace años en otros lenguajes de programación, pero nunca me había puesto a pensar en cómo implementarlo en Bash. Y la verdad es que no es tan complicado como parece. La idea es tener un sistema que me permita crear y aplicar cambios en la estructura de la base de datos de manera controlada y versionada.
Sí, me inspiré en Laravel, pero con mi toque personal (mal hecho).
┌─────────────────────────────────────────────────────────────────────────────┐
│ ARQUITECTURA DE MIGRACIONES │
└─────────────────────────────────────────────────────────────────────────────┘
make_migration.sh migrations/ migrate.sh
───────────────── ─────────── ──────────
│ │ │
│ 1. Genera │ │ 3. Ejecuta
├────────────────────────>│ │
│ │ │
│ ┌─────────────┐ │
│ │ Timestamp │ │
│ │ + Nombre │ │
│ │ = Archivo │ │
│ └─────────────┘ │
│ │ │
│ │ 2. Almacena │
│ ├────────────────────────>│
│ │ │
│ ▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ 20250915_ │ │ SQLite DB │
│ 220501_users.sh │────>│ ┌─────────────┐ │
│ │ │ │ migrations │ │
│ up() / down() │ │ │ table │ │
└─────────────────┘ │ └─────────────┘ │
│ │ ┌─────────────┐ │
│ │ │ users table │ │
└──────────────>│ └─────────────┘ │
└─────────────────┘
Esto lo que me permite es tener un control total sobre la estructura de la base de datos, y poder aplicar cambios de manera segura y controlada. Cada migración tiene una función up para aplicar los cambios y una función down para revertirlos. Esto es especialmente útil en entornos de desarrollo y producción, donde los cambios en la base de datos deben ser gestionados cuidadosamente.
Además agregué unos tipos de datos personalizados para facilitar la creación de tablas:
┌───────────────────────────────────────────────────────────┐
│ SCHEMA BUILDER FUNCTIONS │
└───────────────────────────────────────────────────────────┘
TIPOS DE COLUMNA:
┌─────────────────────────────────────────┐
│ id_column() │
│ └─> "id INTEGER PRIMARY KEY AUTOINCREMENT" │
│ │
│ string_column("name", 255, false) │
│ └─> "name TEXT NOT NULL" │
│ │
│ integer_column("count", false) │
│ └─> "count INTEGER NOT NULL" │
│ │
│ boolean_column("active", "1", false) │
│ └─> "active BOOLEAN DEFAULT 1 NOT NULL" │
│ │
│ datetime_column("created_at", "now", false) │
│ └─> "created_at DATETIME DEFAULT │
│ CURRENT_TIMESTAMP NOT NULL" │
│ │
│ timestamps_columns() │
│ └─> "created_at DATETIME DEFAULT │
│ CURRENT_TIMESTAMP NOT NULL, │
│ updated_at DATETIME DEFAULT │
│ CURRENT_TIMESTAMP NOT NULL" │
└─────────────────────────────────────────┘
RESTRICCIONES:
┌─────────────────────────────────────────┐
│ foreign_key("user_id", "users", "id") │
│ └─> "FOREIGN KEY (user_id) │
│ REFERENCES users(id)" │
│ │
│ unique_constraint("email") │
│ └─> "UNIQUE (email)" │
│ │
│ unique_constraint("name, category_id") │
│ └─> "UNIQUE (name, category_id)" │
└─────────────────────────────────────────┘
ÍNDICES:
┌─────────────────────────────────────────┐
│ create_index("idx_users_email", │
│ "users", "email", true) │
│ └─> "CREATE UNIQUE INDEX IF NOT EXISTS │
│ idx_users_email ON users (email);" │
│ │
│ drop_index("idx_users_email") │
│ └─> "DROP INDEX IF EXISTS │
│ idx_users_email;" │
└─────────────────────────────────────────┘
Con esto puedo crear tablas de manera sencilla y rápida, sin tener que preocuparme por los detalles de SQL. Por ejemplo, para crear una tabla de usuarios con username, email, password, is_active y timestamps, puedo hacer lo siguiente:
./make_migration.sh users
# Lo genera en migrations/20250916_000501_users.sh
Ya solo tengo que editar el archivo generado y definir la estructura de la tabla en la función up:
#!/bin/bash
# Migration: users
# Created: Mon Sep 16 00:05:01 AM CST 2025
source "$(dirname "$0")/../framework/migration.sh"
up() {
echo "Running migration: users"
local columns="$(id_column),
$(string_column "username"),
$(string_column "email"),
$(string_column "password"),
$(boolean_column "is_active" "1"),
$(timestamps_columns)"
create_table "users" "$columns"
}
down() {
echo "Rolling back migration: users"
drop_table "users"
}
# Execute the migration function based on the argument
if [ "$1" = "up" ]; then
up
elif [ "$1" = "down" ]; then
down
else
echo "Usage: $0 {up|down}"
exit 1
fi
Para aplicar la migración, simplemente ejecuto el script migrate.sh:
./migrate.sh
Y listo, la tabla de usuarios se crea en la base de datos. Si en algún momento necesito revertir la migración, puedo ejecutar:
./migrate.sh rollback
ShellRest
Es momento de la verdad, aquí está en funcionamiento completo del framework:
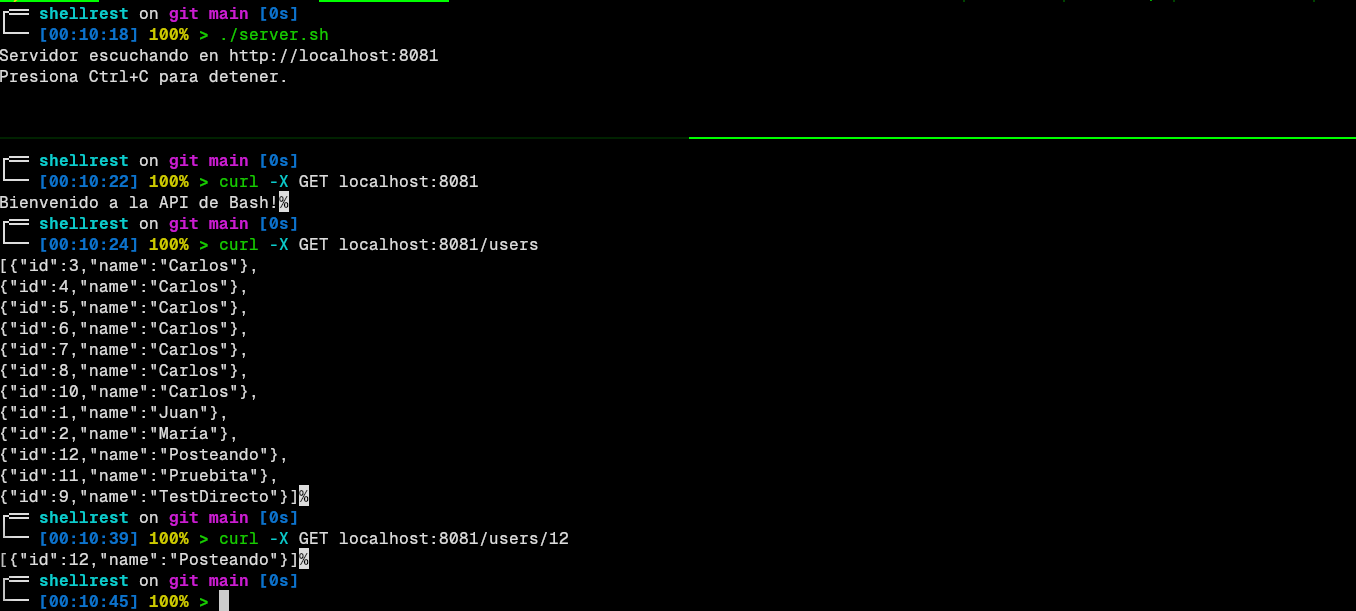
Para ver el código completo y la documentación, visita el repositorio en GitHub:
Conclusión
No cabe duda de que Bash es un lenguaje poderoso y versátil, y con un poco de ingenio y paciencia se pueden lograr cosas increíbles. ShellRest es un ejemplo de ello, un framework para crear API Rest en Bash, que aunque no es perfecto, cumple con su propósito y me ha enseñado mucho en el proceso. Sin dudas se va dirercto a mi portafolio.
Entre disparos por el 15 de septiembre y perros ladrando, me despido. Espero que este proyecto inspire a otros a explorar las posibilidades de Bash y a crear sus propias herramientas y frameworks. ¡Feliz scripting!
"La creatividad es la inteligencia divirtiéndose."
